
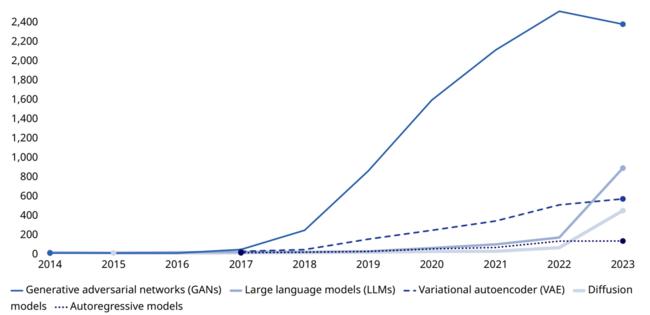
세계지식재산권기구(World Intellectual Property Organization, WIPO)에서 24.7월 발표한 생성형 AI 특허 동향 보고서(Patent Landscape Report : Generative Artificial Intelligence)에 따르면, 14~23년에 생성형 AI 모델의 대부분은 GAN 모델이 차지하고 있으나 최근 들어 추이가 바뀌고 있다.
 14~23년, 생성형 AI 모델의 특허 추이 (이미지=WIPO)
14~23년, 생성형 AI 모델의 특허 추이 (이미지=WIPO)
최근 10년간 생성형 AI 모델 특허의 증가량을 살펴보면, GAN 모델 특허가 가장 많이, 급격하게 증가해 왔으나 21년부터 점차 둔화하는 모습을 보인다. 반면에 LLM 모델 특허는 20년 53개에서 23년 881개로, Diffusion 모델 특허는 20년 18개에서 23년 441개로 가파르게 증가하고 있다.
△ 생성형 AI(Generative Artificial Intelligence, GenAI)
ㅣ 이용자의 특정 요구에 따라 결과물을 만들어내는 AI 기술을 말한다.
ㅣ 이용자의 특정 요구를 해결하기 위해 데이터를 학습하고, 학습된 데이터와 최대한 같아지는 텍스트, 이미지, 오디오, 비디오 등 새로운 데이터를 생성한다.
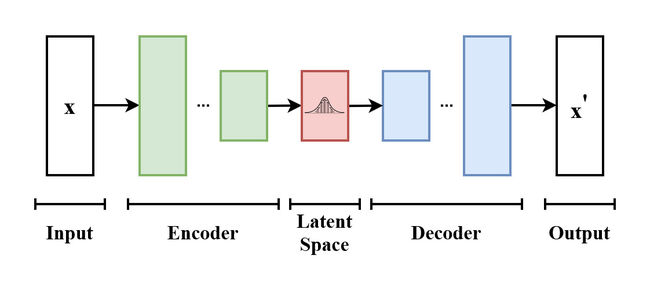
△ VAE(Variational AutoEncoder) 모델
 VAE 프로세스 (이미지=Wikimedia)
VAE 프로세스 (이미지=Wikimedia)
ㅣ VAE는 AE의 구조에 확률 모델링 방법을 결합한 기술이다.
ㅣ AE(AutoEncoder)는 입력 데이터와 출력 데이터가 최대한 같아지도록 복원하는 것이 목적이다. 입력 데이터의 특징을 학습하는 Encoder, 특징을 저장하는 Latent Space, 특징에서 입력 데이터를 최대한 복원하는 Decoder의 구조를 가진다.
ㅣ VAE는 입력 데이터의 확률분포를 학습하는 Encoder, 확률분포를 저장 및 확률분포에서 샘플을 추출하는 Latent Space, 통계적 추론을 통해 입력 데이터와 최대한 같아지는 새로운 데이터를 생성하는 Decoder의 구조를 가진다.
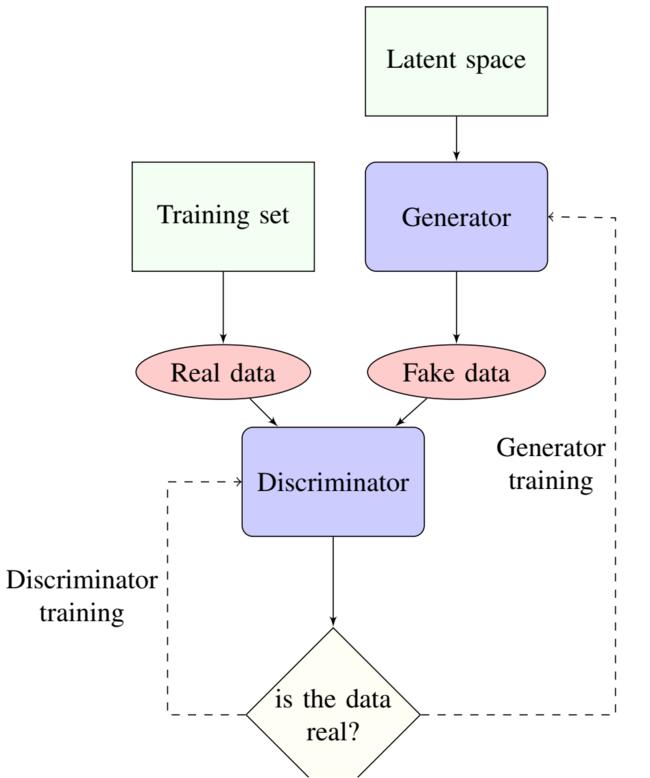
△ GAN(Generative Adversarial Network) 모델
 GAN 프로세스 (이미지=Wikimedia)
GAN 프로세스 (이미지=Wikimedia)
ㅣ 생성자(Generator)와 판별자(Discriminator), 두 개의 요소가 서로 게임을 하듯 경쟁하는 과정을 반복함으로써 모델을 최적화한다.
ㅣ 생성자는 실제(진짜) 데이터와 최대한 같아지는 가짜 데이터를 생성하고, 판별자는 생성자가 만들어낸 가짜 데이터가 실제(진짜)인지 가짜인지 판별한다.
ㅣ 판별자가 생성자의 가짜 데이터를 실제(진짜) 데이터로 판별하면 게임이 끝나고, 그 결과를 반영한 모델이 만들어진다.
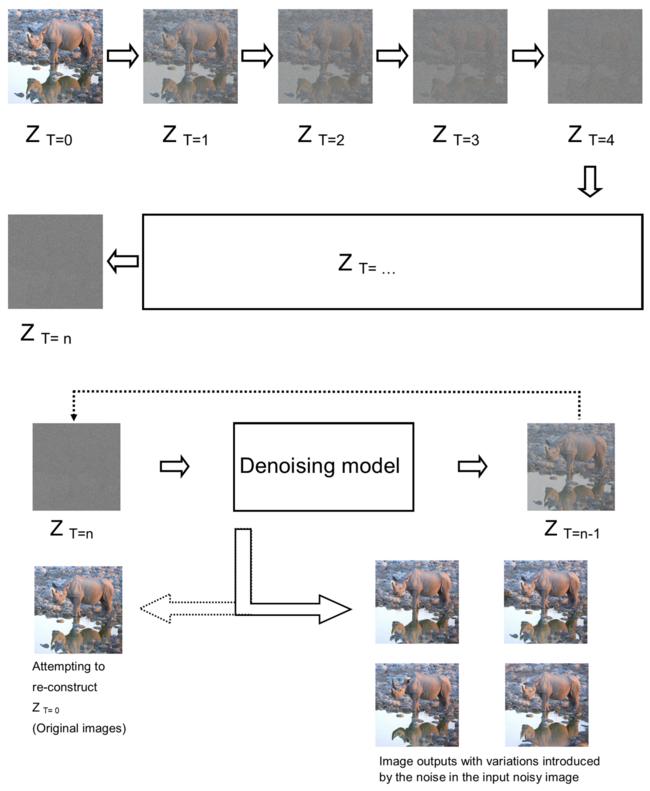
△ Diffusion 모델
 Diffusion(Noising, Denoising) 프로세스 (이미지=Wikimedia)
Diffusion(Noising, Denoising) 프로세스 (이미지=Wikimedia)
ㅣ 물에 떨어뜨린 물감이 퍼지는 것처럼, 노이즈가 확산하거나 반대로 줄어드는 과정을 활용한 기술이다.
ㅣ 데이터에 노이즈를 조금씩 추가/확산하여 패턴을 없애는 노이징(Noising) 과정과 이를 다시 복원하는 디노이징(Denoising) 과정을 학습하여, 특정 노이즈 상태에서 실제 데이터와 최대한 같아지는 새로운 데이터를 생성한다.
ㅣ OpenAI의 소라(Sora)는 Diffusion 모델과 Transformer 모델이 합쳐진 DiT(Diffusion Transformer) 모델로 만들어졌다.
△ LLM(Large Language Model) 모델
 LLM 프로세스 (이미지=Wikimedia)
LLM 프로세스 (이미지=Wikimedia)
ㅣ 인간과 기계 간의 자연스러운 대화를 위한 핵심 기술로, 기계가 인간의 언어를 학습하여 이해하고, 생성하는 머신러닝/딥러닝 기반의 기술이다.
ㅣ OpenAI의 GPT(Generative Pre-trained Transformer) 시리즈, 구글(Google)의 BERT나 Gemini 등이 대표적인 LLM 모델이다.
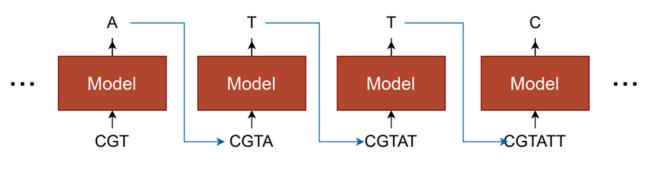
△ Autoregressive 모델
 Autoregressive 프로세스 (이미지=ResearchGate)
Autoregressive 프로세스 (이미지=ResearchGate)
ㅣ 과거의 데이터로 미래를 예측할 수 있다는 시계열 모델링 방법을 활용한 기술이다.
ㅣ 과거 데이터의 특징을 학습하여 이것과 최대한 같아지는 새로운 데이터를 계속 생성함으로써 최종 결과물을 만들어낸다.
 14~23년, 기업별 생성형 AI 특허 현황 (이미지=WIPO)
14~23년, 기업별 생성형 AI 특허 현황 (이미지=WIPO)
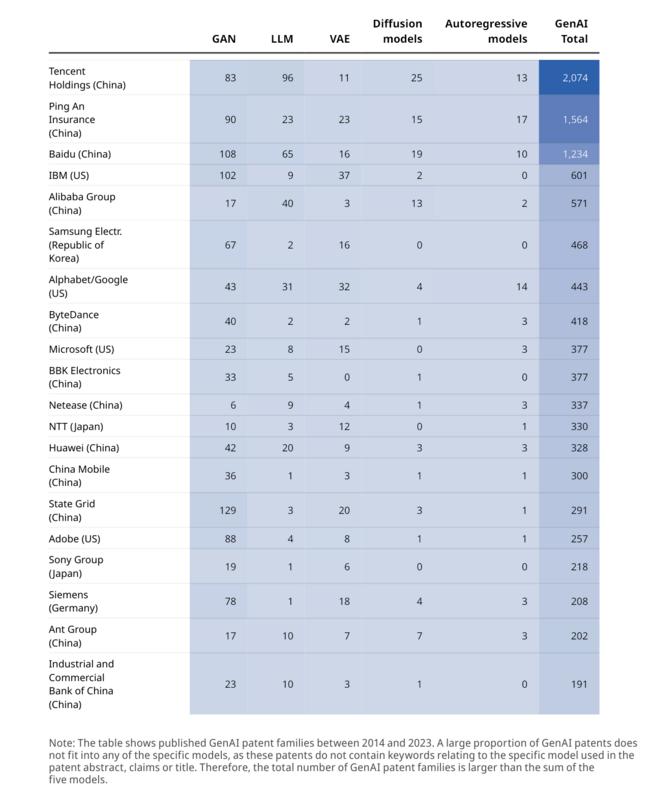
최근 10년간 생성형 AI 특허 중 기업이 소유한 특허를 살펴보면, 중국이 상위권을 점유하고 있다. 텐센트(Tencent)가 2,074건으로 가장 많은 특허를 소유하고 있으며, 핑안보험(Ping An Insurance)이 1,564건으로 2위, 바이두(Baidu)가 1,234건으로 3위를 기록했다. 여기에 중국의 알리바바 그룹(Alibaba Group)이 5위로 571건을, 바이트댄스(ByteDance)가 8위로 418건을, BBK전자(BBK Electronics)가 10위로 377건을 소유하고 있을 정도로 중국의 강세가 눈에 띈다.
우리나라는 유일하게 삼성전자가 468건으로 6위를 기록하고 있다. 미국은 IBM이 601건으로 4위를, 알파벳/구글(Alphabet/Google)이 443건으로 7위를, 마이크로소프트(Microsoft)가 377건으로 10위를 기록했다.
 14~23년, 국가별 생성형 AI 특허 현황 (이미지=WIPO)
14~23년, 국가별 생성형 AI 특허 현황 (이미지=WIPO)
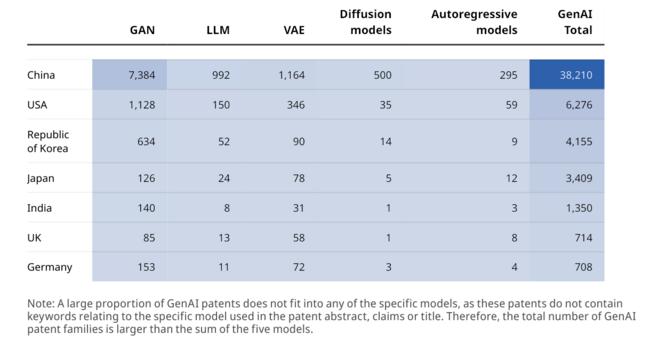
최근 10년간 국가별 생성형 AI 특허를 살펴보면 역시 중국이 38,210건으로 가장 많고, 뒤이어 미국이 6,276건으로 2위, 우리나라가 4,155건으로 3위를 기록하고 있다.
특히 중국은 생성형 AI의 5개 모델 모두에서 우위를 점하고 있다. 미국은 VAE 모델과 LLM 모델에서, 우리나라는 GAN 모델에서 강한 모습을 보인다.

 한국 주식을 언제든/어디서든/믿고/편리하게 살 수 있게 시간/공간/불신/불편 장벽 해소
한국 주식을 언제든/어디서든/믿고/편리하게 살 수 있게 시간/공간/불신/불편 장벽 해소
 현대자동차그룹 '2026 CES 선언'의 의미
현대자동차그룹 '2026 CES 선언'의 의미
 21세기 천상열차분야지도, 스피어엑스 우주 지도
21세기 천상열차분야지도, 스피어엑스 우주 지도
 한일 정상회담 및 주요 성과 관련 대국민보고
한일 정상회담 및 주요 성과 관련 대국민보고
 혐오하지 않을 용기
혐오하지 않을 용기
 목록
목록









